Stochastik
Тематический план
-
-
Hier finden Sie eine Einführung in das Thema bei studyflix.
-
-
Alle Themen
-
Für Fachinformatiker, im Rahmen der IHK-Ausbildungsverordnung, sind bestimmte Teilgebiete der Stochastik besonders relevant. Diese beziehen sich in der Regel auf die Grundlagen der Wahrscheinlichkeitsrechnung und Statistik, die für die Datenanalyse, in der Qualitätssicherung, Algorithmenentwicklung und Entscheidungsfindung in der Informatik wichtig sind. Hier sind einige der Schlüsselbereiche der Stochastik, die für Fachinformatiker wichtig sein könnten:



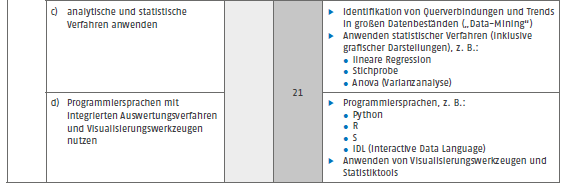
Für Fachinformatiker/-in Daten- und Prozessanalyse dazu
1. Grundlagen der Wahrscheinlichkeitsrechnung
- Wahrscheinlichkeitsbegriff: Verständnis von Zufallsexperimenten, Ergebnismenge, Ereignissen und der Wahrscheinlichkeit von Ereignissen.
- Kombinatorik: Grundlegende Prinzipien der Kombinatorik wie Permutationen, Kombinationen und Variationen, die bei der Berechnung der Anzahl von möglichen Ausgängen eines Ereignisses helfen.
2. Bedingte Wahrscheinlichkeit und Unabhängigkeit
- Verständnis von bedingten Wahrscheinlichkeiten, insbesondere im Kontext von Algorithmen, die auf Wahrscheinlichkeiten basieren, wie zum Beispiel bei der Spam-Erkennung oder in der Bayesschen Statistik.
- Konzepte der Unabhängigkeit und Abhängigkeit von Ereignissen.
3. Verteilungsfunktionen und Kennzahlen
- Kenntnisse verschiedener Wahrscheinlichkeitsverteilungen (Binomialverteilung, Normalverteilung etc.) und deren Anwendungsbereiche.
- Grundlegende statistische Kennzahlen wie Mittelwert, Median, Modus, Varianz und Standardabweichung, die zur Datenanalyse und -interpretation verwendet werden.
4. Stochastische Prozesse
- Grundlegendes Verständnis stochastischer Prozesse kann nützlich sein, vor allem bei der Modellierung und Analyse von Systemen, die über die Zeit variieren (z.B. Netzwerkverkehr, Warteschlangensysteme).
5. Anwendungsbereiche in der Informatik
- Algorithmen und Datenstrukturen: Anwendung der Stochastik in Algorithmen, zum Beispiel bei Sortieralgorithmen oder Suchalgorithmen, und in der Analyse der Laufzeitkomplexität.
- Maschinelles Lernen und Künstliche Intelligenz: Grundprinzipien stochastischer Modelle im maschinellen Lernen, z.B. Entscheidungsbäume, Bayes-Netzwerke.
- Netzwerksicherheit und Kryptographie: Wahrscheinlichkeitsbasierte Ansätze zur Absicherung von Daten und Netzwerken.
-
Neben den stochastischen Grundlagen, die für Fachinformatiker wichtig sind, gibt es weitere Themen der Statistik, die in der Ausbildung oder in der beruflichen Weiterbildung von Bedeutung sein können. Diese Themen unterstützen das Verständnis von Daten und deren Analyse, was für die Entwicklung, Optimierung und Analyse von Software und Systemen essentiell ist. Hier sind einige der Schlüsselbereiche:
1. Deskriptive Statistik
- Datenaufbereitung: Methoden zur Datenerfassung und -bereinigung.
- Verteilungsmaße: Detaillierte Behandlung von Streuungsmaßen (Varianz, Standardabweichung) und Lagemaßen (Mittelwert, Median, Modus).
- Visualisierung von Daten: Grundlagen und Techniken zur grafischen Darstellung von Daten, wie Histogramme, Boxplots und Streudiagramme.
2. Inferenzstatistik
- Schätztheorie: Methoden zur Schätzung von Parametern einer Grundgesamtheit basierend auf Stichproben.
- Hypothesentests: Verfahren zur Überprüfung von Annahmen über eine Grundgesamtheit, einschließlich t-Tests, Chi-Quadrat-Tests und ANOVA.
- Konfidenzintervalle: Bestimmung und Interpretation von Konfidenzintervallen für Stichprobenstatistiken.
3. Multivariate Statistik
- Regressionsanalyse: Untersuchung der Beziehungen zwischen einer abhängigen Variable und einer oder mehreren unabhängigen Variablen.
- Faktor- und Clusteranalyse: Methoden zur Reduktion von Datendimensionen und zur Gruppierung von Datensätzen.
4. Zeitreihenanalyse
- Analyse von Daten, die über einen bestimmten Zeitraum gesammelt wurden, zur Identifizierung von Trends, saisonalen Schwankungen und Zyklen.
5. Statistische Software und Programmiersprachen
- Einführung in statistische Software (wie R, Python mit Bibliotheken wie Pandas, NumPy, Matplotlib, Scikit-learn) zur Datenanalyse und -visualisierung.
- Anwendung dieser Tools zur Automatisierung von Analysen, zur Datenbereinigung und zur Entwicklung von Machine-Learning-Modellen.
6. Anwendungsbereiche und Praxisprojekte
- Anwendung der gelernten statistischen Methoden auf reale Daten und Probleme, etwa in der Qualitätskontrolle, bei Benutzerstudien oder in der Auswertung von Leistungsdaten von Systemen.
Für Fachinformatiker sind diese Themen besonders wichtig, um Daten korrekt analysieren, interpretieren und darauf basierend fundierte Entscheidungen treffen zu können.
-
-
-
Der Mittelwert wird zur Beschreibung der zentralen Tendenz einer Datenmenge verwendet. Er gibt den Durchschnittswert aller Beobachtungen in einem Datensatz an und wird oft als repräsentativer Wert für die gesamte Datenmenge betrachtet.
-
Der Median ist ein statistisches Maß, das den mittleren Wert einer geordneten Datenreihe angibt. Anders als der Mittelwert, der durch die Summierung aller Werte und Teilung durch ihre Anzahl berechnet wird, teilt der Median eine sortierte Liste von Zahlen in zwei Hälften. Die eine Hälfte enthält Werte, die kleiner sind als der Median, und die andere Hälfte enthält Werte, die größer sind. Der Median wird oft verwendet, um die zentrale Tendenz einer Datenmenge zu beschreiben, besonders wenn die Datenverteilung sehr asymmetrisch ist oder Ausreißer enthält, da er von diesen weniger beeinflusst wird als der Mittelwert.
-
Der Modus, auch Modalwert genannt, ist ein weiteres Maß der zentralen Tendenz in der Statistik. Er bezeichnet den oder die Werte in einer Datenmenge, die am häufigsten vorkommen.
-
In der Statistik und Forschungsmethodik unterscheidet man verschiedene Skalenniveaus, um Daten zu klassifizieren. Diese Skalenniveaus geben Auskunft darüber, welche mathematischen Operationen mit den Daten sinnvoll durchgeführt werden können und welche statistischen Analysen angemessen sind.
-
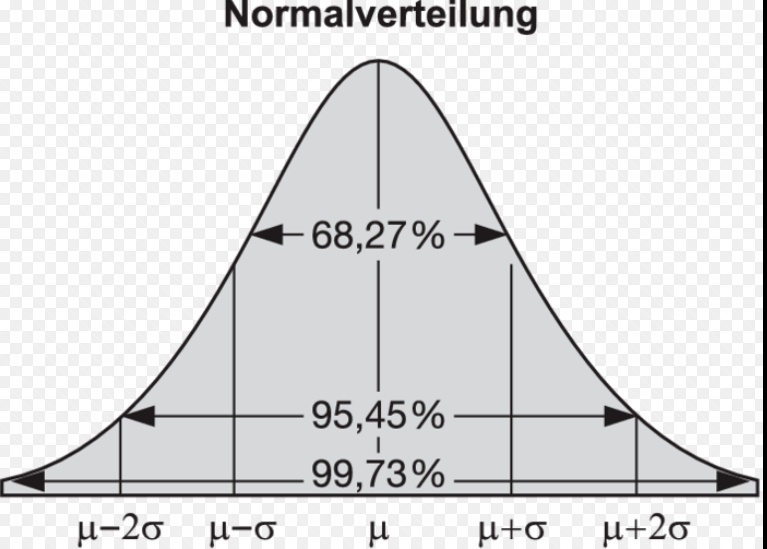
Die Standardabweichung ist ein Maß für die Streuung oder Variabilität von Datenpunkten in einer Datenreihe um ihren Mittelwert. Sie zeigt, wie weit die einzelnen Werte im Durchschnitt vom Mittelwert der gesamten Datenmenge entfernt liegen. Eine geringe Standardabweichung bedeutet, dass die meisten Datenpunkte nah am Mittelwert liegen, während eine hohe Standardabweichung darauf hinweist, dass die Daten über einen breiteren Bereich verteilt sind.
-
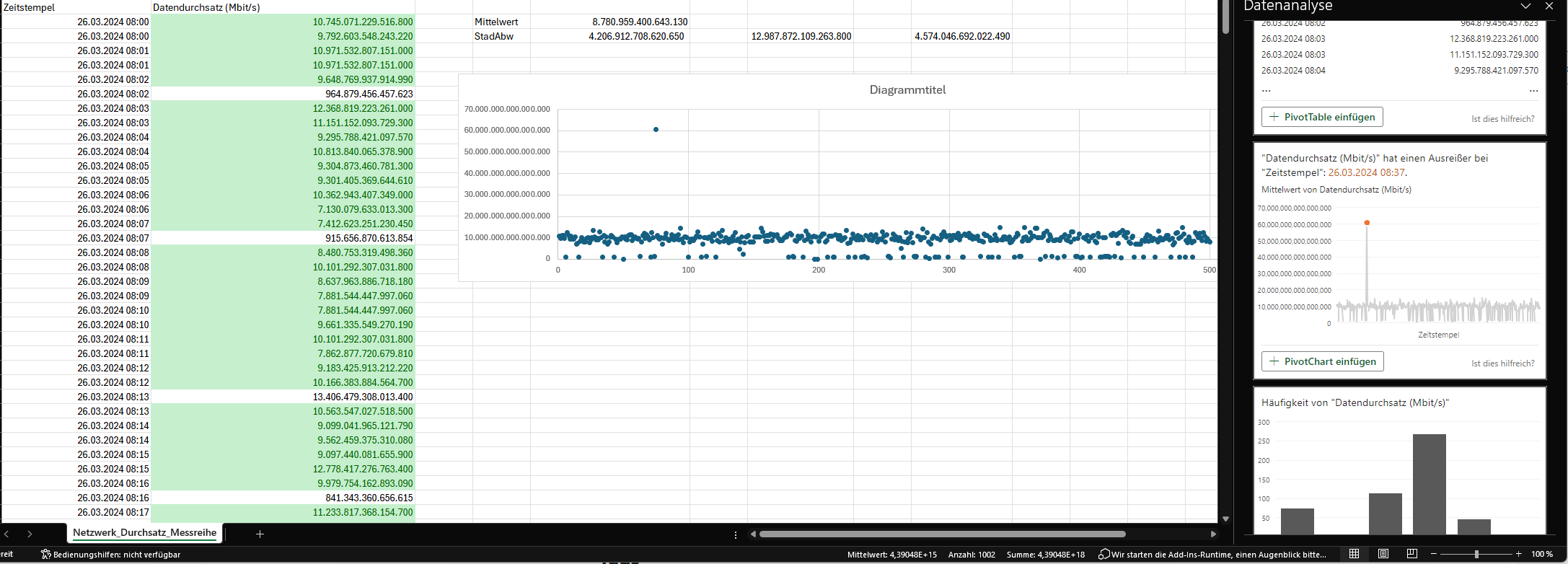
Die Messreihe mit Datendurchsätzen aus einem Netzwerk zeigt die Durchsätze in Megabit pro Sekunde (Mbit/s) welche in einem Unternehmensnetzwerk gemessen werden konnten.
-
Auswertungen
-
-
-
-
