Unüberwachtes Lernen (Unsupervised Learning)
- Clustering: Gruppierung von Datenpunkten in Cluster (z.B. Kunden-Segmentierung).
- Algorithmen: k-Means, Hierarchisches Clustering, DBSCAN.
- Dimensionalitätsreduktion: Reduktion der Anzahl der Merkmale, während die wesentlichen Informationen erhalten bleiben (z.B. PCA - Principal Component Analysis).
- Algorithmen: PCA, t-SNE, UMAP.
Clustering und Hierarchisches Clustering
Clustering ist eine Methode im maschinellen Lernen, um Datenpunkte in Gruppen (Cluster) zu unterteilen, sodass Datenpunkte in einem Cluster ähnlicher zueinander sind als zu Datenpunkten in anderen Clustern. Ein konkretes Anwendungsbeispiel für Clustering ist die Kundensegmentierung, bei der Kunden basierend auf ihren Merkmalen (z.B. Kaufverhalten, demografische Daten) in Segmente gruppiert werden.
Hierarchisches Clustering
Hierarchisches Clustering ist eine Methode, bei der Cluster in einer hierarchischen Struktur (dendritische Struktur) organisiert werden. Es gibt zwei Hauptansätze für hierarchisches Clustering:
- Agglomeratives Clustering (Bottom-up)
- Divisives Clustering (Top-down)
Beispiel: KundensegmentierungAngenommen, wir haben eine Kundendatenbank mit den Merkmalen Jahreseinkommen und Ausgabengewohnheiten. Wir möchten die Kunden in Gruppen einteilen, die sich in Bezug auf diese Merkmale ähneln.
Implementierung in Python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from scipy.cluster.hierarchy import fcluster
# Beispiel-Daten
data = {
'Kunde': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'],
'Jahreseinkommen': [15, 16, 14, 14, 18, 19, 16, 15, 18, 19],
'Ausgabengewohnheiten': [39, 81, 6, 77, 40, 76, 6, 77, 40, 78]
}
df = pd.DataFrame(data)
# Merkmale (ohne die Kundennamen)
X = df[['Jahreseinkommen', 'Ausgabengewohnheiten']]
# Hierarchisches Clustering durchführen
Z = linkage(X, method='ward')
# Dendrogramm plotten
plt.figure(figsize=(10, 7))
plt.title("Dendrogramm für hierarchisches Clustering")
dendrogram(Z, labels=df['Kunde'].values)
plt.show()
# Cluster-Zuordnung bei einem gewählten Schwellenwert
threshold = 25 # dies kann angepasst werden
clusters = fcluster(Z, threshold, criterion='distance')
df['Cluster'] = clusters
print(df)
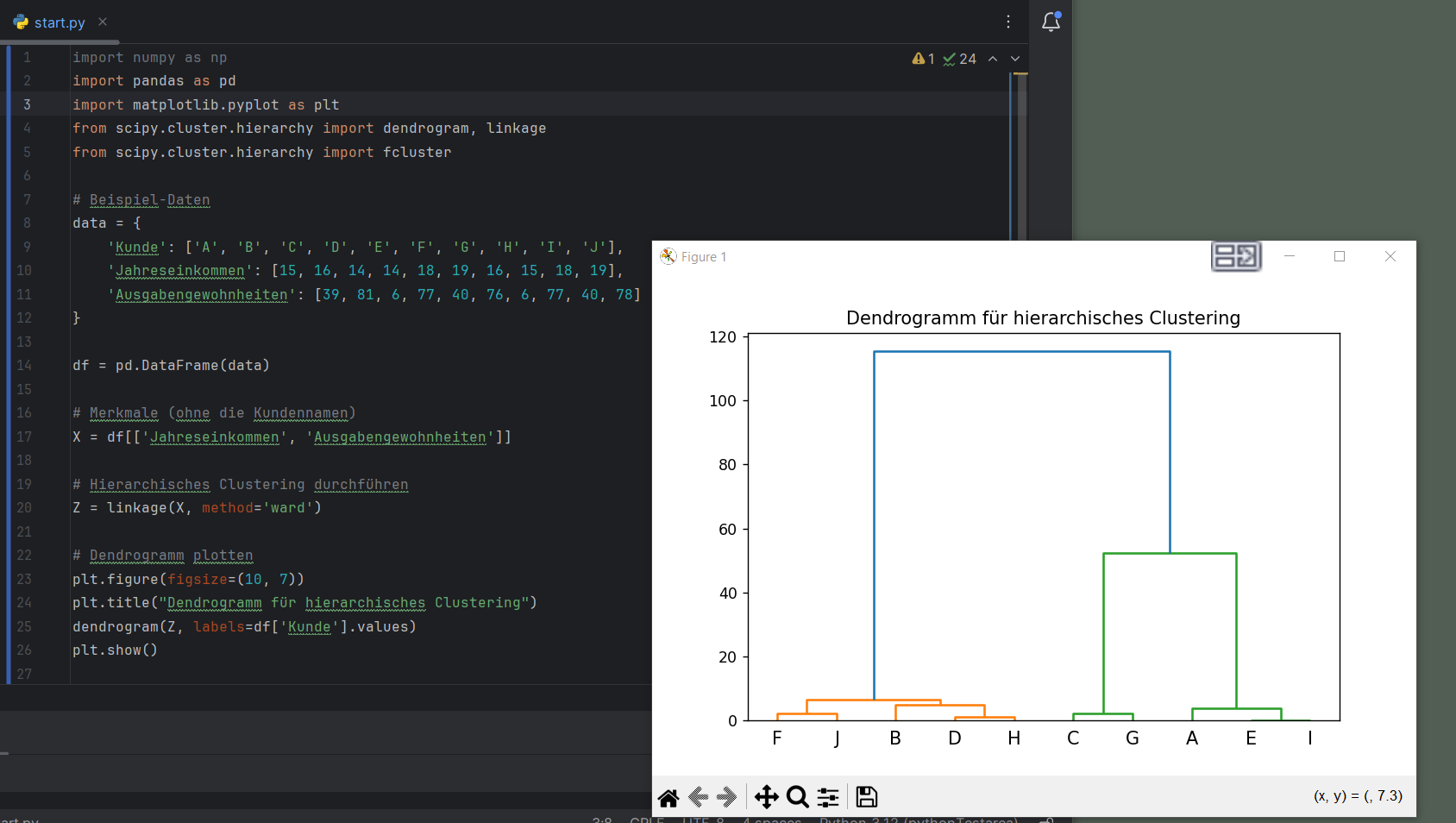
- 2 große Cluster von F J B D und H sowie C G A E und I gebildet werden.
- das linke Cluster kann geteil werden in F J und B D H.