Künstliche Intelligenz und Maschinenlernen
Topic outline
-
Definition und Geschichte
-
Künstliche Intelligenz (KI):
Der Bereich der Informatik, der sich mit der Entwicklung von Systemen befasst, die Aufgaben übernehmen können, die normalerweise menschliche Intelligenz erfordern. Dazu gehören das Lernen, Schlussfolgern, Problemlösen, Verstehen natürlicher Sprache und Wahrnehmung.
-
-
- Überblick: Grundkonzepte des maschinellen Lernens, Unterschiede zwischen überwachten, unüberwachten und verstärkenden Lernmethoden.
- Algorithmen: Einführung in grundlegende ML-Algorithmen wie lineare Regression, Entscheidungsbäume, K-Nearest Neighbors (KNN) usw.
- Python-Bibliotheken: Nutzung von Bibliotheken wie Scikit-Learn, TensorFlow oder PyTorch für einfache ML-Projekte.
-
Maschinelles Lernen ist ein Teilgebiet der Künstlichen Intelligenz, das sich mit der Entwicklung von Algorithmen und statistischen Modellen beschäftigt, die Computer in die Lage versetzen, aus Daten zu lernen und Vorhersagen oder Entscheidungen zu treffen, ohne explizit dafür programmiert zu sein.
Maschinelles Lernen umfasst verschiedene Ansätze, um aus Daten zu lernen und Modelle zu erstellen, die Vorhersagen treffen oder Entscheidungen treffen können.
-
Überwachtes Lernen ist ein Lernparadigma, bei dem das Modell mit gekennzeichneten Daten trainiert wird, d.h. jeder Trainingsdatensatz besteht aus Eingabewerten (Features) und der zugehörigen Zielvariable (Label).
-
Unüberwachtes Lernen ist ein Lernparadigma, bei dem das Modell mit unbeschrifteten Daten trainiert wird, d.h. es gibt keine Zielvariable. Ziel ist es, verborgene Muster oder Strukturen in den Daten zu erkennen.
-
Verstärkendes Lernen (RL) ist ein Bereich des maschinellen Lernens, bei dem ein Agent in einer Umgebung agiert, um eine Belohnung zu maximieren. Der Agent lernt durch Interaktion mit der Umgebung und passt sein Verhalten basierend auf den erhaltenen Belohnungen an. Im Gegensatz zu überwachten Lernmethoden, bei denen der Agent mit gekennzeichneten Daten trainiert wird, lernt der Agent im RL aus den Konsequenzen seiner Aktionen.
Verstärkendes Lernen ist ein mächtiges Paradigma, bei dem ein Agent durch Interaktion mit seiner Umgebung und durch Rückmeldungen in Form von Belohnungen lernt. Durch den Einsatz verschiedener Algorithmen, von einfachen tabellarischen Methoden wie Q-Learning bis hin zu komplexen neuronalen Netzwerken wie DQN, kann der Agent lernen, effektive Strategien zur Maximierung langfristiger Belohnungen zu entwickeln.
-
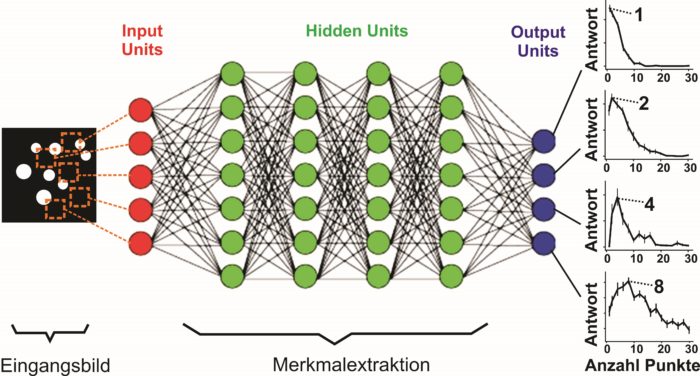
Neuronale Netze, auch künstliche neuronale Netze (KNN) genannt, sind eine Klasse von Algorithmen im maschinellen Lernen, die inspiriert sind von der Struktur und Funktionsweise des menschlichen Gehirns. Sie bestehen aus Neuronen, die in Schichten organisiert sind und miteinander verbunden sind, um komplexe Muster und Beziehungen in Daten zu lernen.
-
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# Daten laden
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Daten normalisieren und one-hot kodieren
x_train = x_train / 255.0
x_test = x_test / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# Modell definieren
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# Modell kompilieren
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Modell trainieren
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
# Modell bewerten
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_acc}')
-
GPT gehört zu den generativen Modellen und wird hauptsächlich für Anwendungen in der natürlichen Sprachverarbeitung verwendet. Es nutzt die Transformer-Architektur, um Text zu generieren, der kontextuell relevant und kohärent ist. Seine Fähigkeit, große Mengen an Textdaten zu verarbeiten und zu verstehen, macht es zu einem mächtigen Werkzeug in vielen NLP-Anwendungen, von Textgenerierung über Übersetzung bis hin zu Fragebeantwortung und Dialogsystemen.
-
Generative Modelle
Generative Modelle lernen, Daten zu erzeugen, die der Verteilung der Trainingsdaten ähnlich sind. Sie modellieren die zugrunde liegende Datenverteilung und können neue Datenpunkte erzeugen, die in diese Verteilung passen. GPT nutzt diese Eigenschaft, um menschenähnliche Texte zu generieren.
Natürliche Sprachverarbeitung (NLP)
NLP ist ein Bereich des maschinellen Lernens, der sich mit der Interaktion zwischen Computern und menschlicher Sprache beschäftigt. Modelle wie GPT werden für Aufgaben in der natürlichen Sprachverarbeitung verwendet, darunter:
1. Textgenerierung: GPT kann kohärenten Text auf Basis eines gegebenen Anfangs generieren.
2. Übersetzung: GPT kann als Teil von Übersetzungssystemen verwendet werden, indem es Texte von einer Sprache in eine andere übersetzt.
3. Zusammenfassung: GPT kann längere Texte zusammenfassen, indem es die wichtigsten Informationen extrahiert.
4. Fragebeantwortung: GPT kann Antworten auf Fragen generieren, indem es relevante Informationen aus Texten extrahiert.
5. Dialogsysteme: GPT kann in Chatbots und anderen Dialogsystemen eingesetzt werden, um menschenähnliche Gespräche zu führen.Architektur von GPT
GPT basiert auf der Transformer-Architektur, die von Vaswani et al. in dem Papier "Attention is All You Need" vorgestellt wurde. Hier sind einige wichtige Komponenten der Architektur:
1. Selbstaufmerksamkeit (Self-Attention): Diese Mechanismus erlaubt es dem Modell, bei der Verarbeitung eines Wortes auf alle anderen Wörter im gleichen Satz zu achten. Dies verbessert das Verständnis von Kontext und Abhängigkeiten in einem Text.
2. Positionskodierungen (Positional Encodings): Da Transformermodelle keine inhärente Reihenfolge der Eingabedaten haben, werden Positionskodierungen hinzugefügt, um die Position der Wörter im Satz zu berücksichtigen.
3. Schichten (Layers): GPT besteht aus mehreren hintereinander geschalteten Transformerschichten, die jede Eingabe durch mehrere Stufen der Selbstaufmerksamkeit und Feedforward-Netze verarbeiten.
4. Prätraining und Feinabstimmung (Fine-Tuning):
- Prätraining: GPT wird zunächst auf einem großen Textkorpus trainiert, um eine allgemeine Sprachmodellierung zu lernen.
- Feinabstimmung: Nach dem Prätraining wird das Modell auf spezifischere Aufgaben oder Daten angepasst, um seine Leistung in bestimmten Anwendungsbereichen zu optimieren.
Beispiel für die Verwendung von GPT
Ein einfacher Code zur Nutzung von GPT-3 mittels der OpenAI-API in Python könnte folgendermaßen aussehen:import openai
# OpenAI API-Schlüssel
openai.api_key = 'YOUR_API_KEY'
# Anfrage an GPT-3
response = openai.Completion.create(
engine="davinci-codex",
prompt="Schreibe eine kurze Geschichte über einen mutigen Ritter.",
max_tokens=150
)
# Ausgabe des generierten Textes
print(response.choices[0].text.strip())
In diesem Beispiel:
- `engine="davinci-codex"` wählt das GPT-3-Modell aus.
- `prompt` ist der Eingabetext, auf dessen Basis GPT-3 eine Antwort generiert.
- `max_tokens` begrenzt die Länge der generierten Antwort. -
In Python gibt es eine Vielzahl von Bibliotheken und Frameworks, die für künstliche Intelligenz (KI) und maschinelles Lernen (ML) verwendet werden können. Hier sind einige der wichtigsten und am häufigsten verwendeten:
-
GPT, insbesondere GPT-3 und GPT-4, ist darauf trainiert, mehrere Sprachen zu verstehen und darauf zu reagieren. Es wurde auf einer breiten Palette von Texten aus dem Internet trainiert, die verschiedene Sprachen abdecken. Dennoch gibt es Unterschiede in der Menge und Vielfalt der Trainingsdaten für verschiedene Sprachen
-
-
-
Die Grundlagen der Linearen Algebra und Wahrscheinlichkeitstheorie sind entscheidend für das Verständnis und die Entwicklung von Methoden in der Künstlichen Intelligenz (KI) und dem Maschinellen Lernen (ML).
-